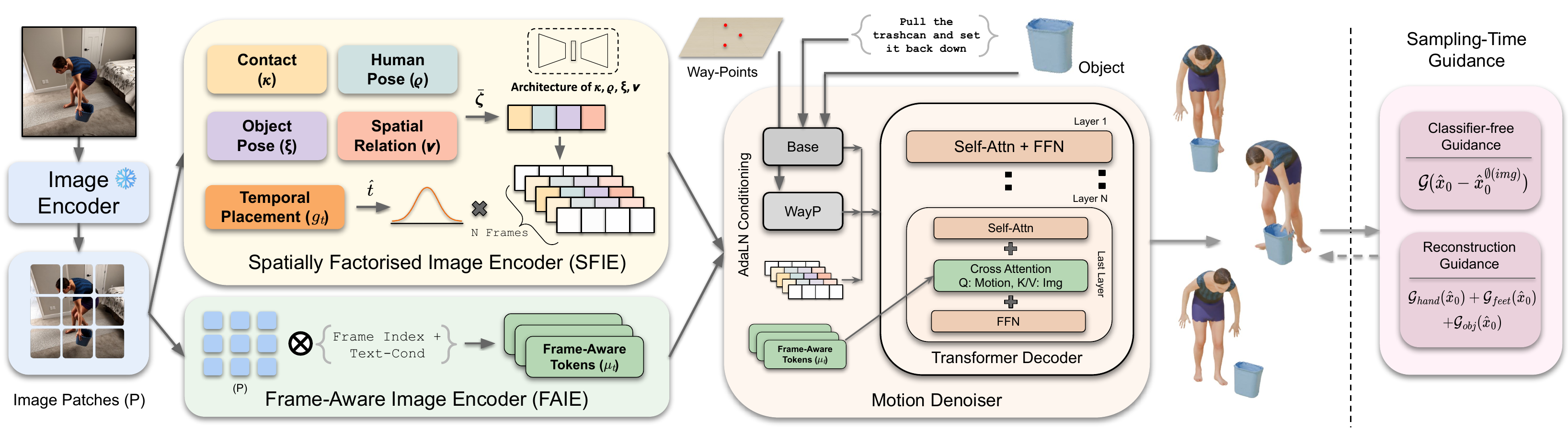
Image-conditioned 4D HOI generation.
Given a text prompt, object geometry, object waypoints, and a
reference image, IMAGIN-4D synthesizes a 4D human-object
interaction sequence. Text and waypoints specify the action and
object trajectory, but leave fine-grained interaction details such
as pose, contact, and layout ambiguous. We resolve this ambiguity
with a reference image that specifies the interaction snapshot.
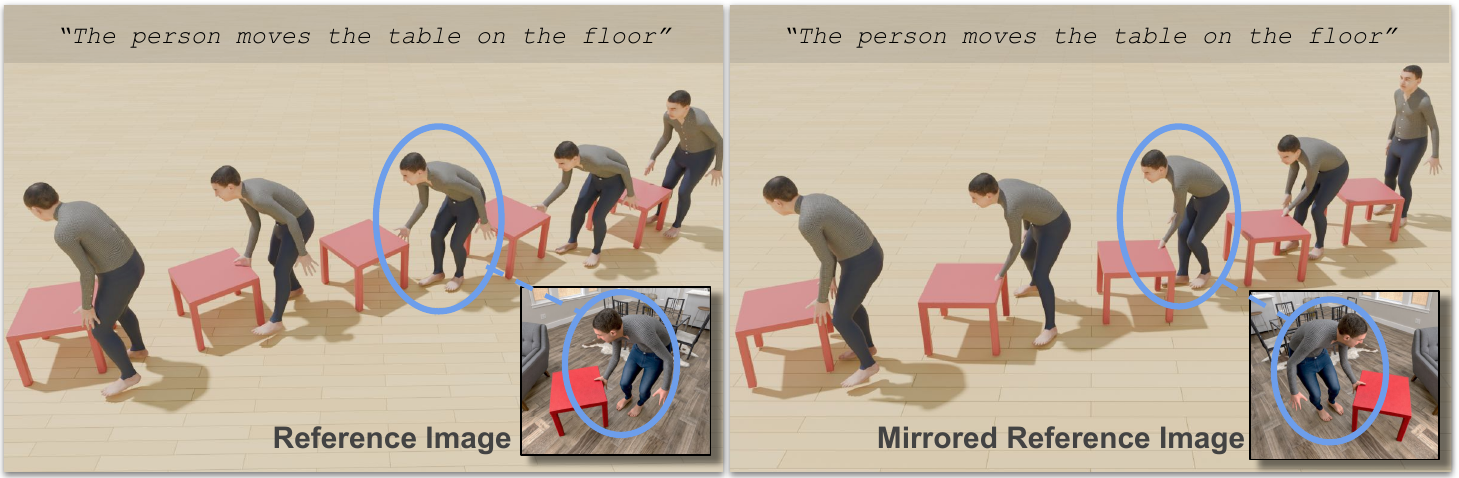
To test whether IMAGIN-4D follows this visual evidence, we keep
the text prompt, object geometry, and waypoints fixed, and mirror
only the reference image. IMAGIN-4D generates different motions
that satisfy the corresponding snapshot: body pose, object pose,
contact, and body-object layout change consistently with the
mirrored reference. This is achieved through spatio-temporal image
conditioning, which separates spatial cues for the depicted
interaction state from frame-aware cues for the surrounding
motion. Unlike single-token image conditioning, this preserves
fine-grained visual evidence while generating the HOI sequence.